Continuous Active Learning for Communications Surveillance

As more and more of our communications become electronic as opposed to face-to-face or analog, the need for communication surveillance programs to adopt Artificial Intelligence (AI) has increased. It has gotten to the point where Natural Language Processing and Machine Learning are no longer nice to-haves but must-haves. This blog will introduce and explore the use of Continuous Active Learning, a machine-learning approach for communication surveillance.
Machine Learning or simply ML, is a branch of AI. Machine Learning is all about training algorithms or sets of algorithms against data to create a model that can be used to accurately predict outcomes.
The idea here is that the machine learns from existing data that has already been classified as X or as Y, as positive or as negative, relevant, or irrelevant. By showing categorized data to a machine learning engine, it learns to tell the categories apart. Machine Learning focuses on figuring out what is unique to each category by relating elements of items such as metadata and content to build a model that can predict which category applies to any new object introduced into the system. And it does not need to be binary, multiclass models also exist.
When I think of an algorithm for Machine Learning, I always think of high school algebra where the slope of a line = mx+b.
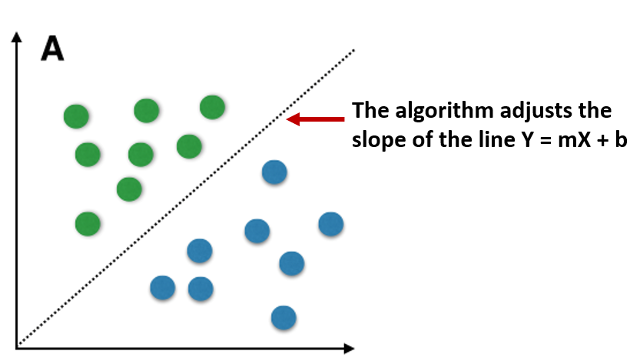
In this case we show the machine all the green and blue dots and ask it to figure out the formula for the slope. This is very much how ML works. You show the machine all the data and you ask it to adjust the slope (m) and the y-intercept (b) while minimizing errors (wrong-colored dots on either side).
Now there are many ways to train a system for Machine Learning, and over time, we have seen a plethora of many types of learning models used to train machines including supervised, unsupervised, and reinforcement-based models. Each of these types contain many further subcategories from linear regression techniques and Naive Bayes to more complex deep learning techniques like those we see in OpenAI and ChatGPT. At the end of the day however, all of these systems require learning. And the resulting efficacy of each of these models is greatly impacted by the learning process itself. How you train a machine to learn is critical.
So how should you train a machine for learning for communication surveillance? There is more than one way to train a model.
One best practice technique to answer this question is to look at related industries and see how machine learning has developed and evaluate if elements there can be incorporated for your use case. In eDiscovery, Machine Learning has often been referred to as Technology Assisted Review (TAR) or as Predictive Coding. The idea is that the machine learns to predict relevance for a specific legal matter(s). And in this industry, we’ve seen the use of Predictive Coding in commercial software since Recommind released Axcelerate back in 2009. Since then, it has been developed and extended a lot.
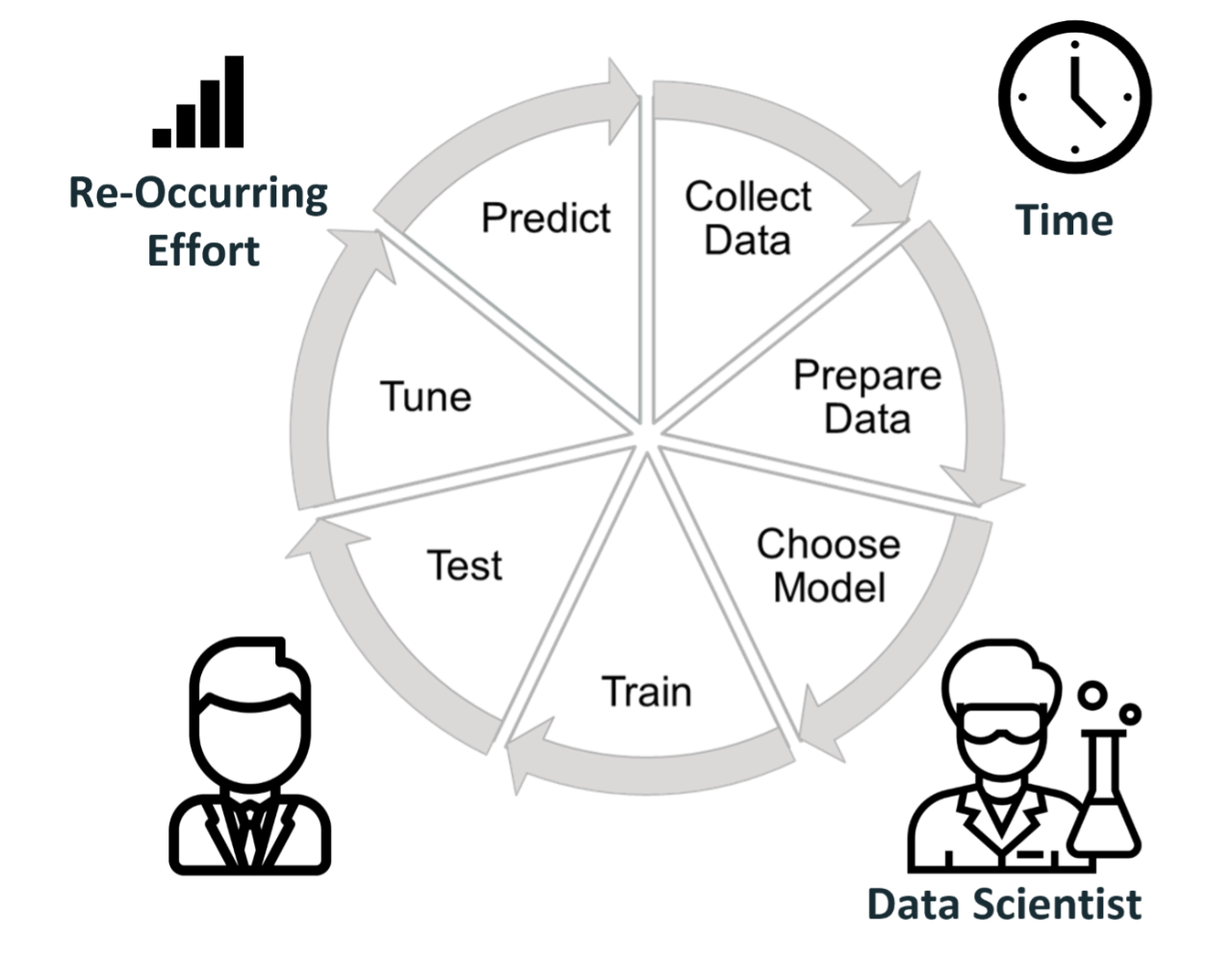
Essentially, this involves a discrete multi-step process. For simplicity let’s just look at this from a high level. It starts with a subject matter expert, someone expertly trained on the data, on the legal case, to hand select items, or portions of items for training and works with a Data Scientist to train the machine learning engine. Basically, telling the machine – this is what items that involve money laundering look like, this is what items that do not contain money laundering look like and so on. This is the training set. The Training set is then used to create the model which is then evaluated against a larger dataset. The results from this evaluation are then used to further train the algorithm which in turn is then retested and these steps are repeated until the model is deemed accurate, and the algorithm is released into production to predict whether new items coming into the system are relevant or irrelevant.
The benefit here is that over several iterations, you can create a model that is very good at predicting whether items are categorized in one way or another. And the more iterations you do, the more accurate your model.
The downside to this approach is that it is very labor intensive. And often requires the availability of highly skilled labor, a subject matter expert, and often, a data scientist, to help properly tune and configure the system. This data scientist may be provided by the vendor. But it still comes at a time and cost expense. The more accurate you want the engine to be, the more expert time and money you will spend.
The other downside is that while this approach can be very accurate on day 1, it then loses accuracy over time. As new data enters the system, as new emails get created, as new violations occur, as our understanding of the violations deepens, the model becomes increasingly inaccurate because the training did not, and cannot, consider these new items. And so, on day 2 the accuracy of the algorithm is less than day 1 and begins to drift from ideal. and on day 3 even more so. And thus, you will need to periodically re-train the system to maintain accuracy – costing you even more expert time and money.

In response to this continuous active learning (CAL) was created. With CAL, there is no discrete, out-of- band multi-step training process. You simply point to items that have already been reviewed. These items have already been classified by your team. The training set is your reviewer history. There is no need to build and cull a special training set or tune the engine. The model then updates itself regularly, as your review team goes through their job every day, and every week, reviewing items.
In essence, the machine simply observes your team in action and learns from them directly, and continuously. There is no need for a subject matter expert or a data scientist to tune your engine. Nor is there a requirement for regularly occurring discrete re-training events. It’s all built right into the system.
The advantage here is that the system never goes stale. In fact, it gets more and more accurate over time. The more data your team reviews, the more accurate the model becomes.
And so, in a lot of ways CAL is really the next generation. That is not to say the older Predictive Coding approach does not have its place. It is still a good model, especially when the data universe is static and does not change frequently. But for surveillance/supervision, as there is always new data, new emails, new challenges and violations, CAL is a great approach.
As reviewers go about their day, reviewing and marking items, this trains the system. And the system then learns to automatically predict relevance on new unreviewed items.
You turn it on at the sample and or search level and it just works. A simple, yet elegant way, to enact Machine Learning into your processes with virtually zero disruption. So, what are you waiting for, learn more about Intelligent Review and how it delivers on Continuous Active Learning by checking out our whitepaper.
